
مقدمة في ترميز النصوص
![]()
كما هو من البديهي، فإن الآلة لا تتعامل مع النصوص بحروفها وأفعالها وأسمائها وأنه يتوجب علينا تحويل هذه النصوص لمعاملات رقمية يمكن للآلة أن تبني خوارزمياتها عليها. بناءً على ذلك، كيف للآلة أن تتعلم أن نصاً معيناً يحمل صفةً إيجابية مثلاً أو سلبية؟ كيف لمحركات البحث أن تفهم عن ماذا نبحث عند ادخالنا لمجموعة من النصوص في حقل الادخال. كل ذلك مبني على مفهوم بسيط يطلق عليه الترميز.
تعلم الآلة دائماً ما يبتدئ ببناء قناة تتدفق منها البيانات عبر مراحل حتى الوصول من خلالها لبناء النموذج. هذه البيانات تحتاج منا لتحويل هذه النصوص لمعاملات رقمية. عملية الترميز هذه تمكننا من بناء نماذج لتعلم الآلة بنفس الآلية لمثيلات هذه البيانات من البيانات الرقمية الأصيلة كمجموع المبيعات وعدد القطع والأوزان وغيرها. تعرف عملية الترميز بمصطلح "Text Encoding".
التقنيات المستخدمة اليوم لترميز النصوص ليست بالمعقدة إطلاقاً وسنستعرض سوية مجموعة منها مع الأمثلة باستخدام لغة بايثون، بالتفصيل. سنستخدم في هذا الشرح مجموعة من النصوص استخرجت من موسوعة ويكيبيديا تتكلم عن عدد الأشجار الموجودة حول العالم.
تعلم الآلة دائماً ما يبتدئ ببناء قناة تتدفق منها البيانات عبر مراحل حتى الوصول من خلالها لبناء النموذج. هذه البيانات تحتاج منا لتحويل هذه النصوص لمعاملات رقمية. عملية الترميز هذه تمكننا من بناء نماذج لتعلم الآلة بنفس الآلية لمثيلات هذه البيانات من البيانات الرقمية الأصيلة كمجموع المبيعات وعدد القطع والأوزان وغيرها. تعرف عملية الترميز بمصطلح "Text Encoding".
التقنيات المستخدمة اليوم لترميز النصوص ليست بالمعقدة إطلاقاً وسنستعرض سوية مجموعة منها مع الأمثلة باستخدام لغة بايثون، بالتفصيل. سنستخدم في هذا الشرح مجموعة من النصوص استخرجت من موسوعة ويكيبيديا تتكلم عن عدد الأشجار الموجودة حول العالم.
corpus = [
"The number of trees in the world, according to a 2015 estimate, is 3.04 trillion.",
"46% of the trees in the world are in the tropics or sub-tropics.",
"20% of the trees in the world are in the temperate zones.",
"24% of threes in the world are in the coniferous boreal forests.",
"There about 15 billion trees are cut down annually.",
"There about 5 billion trees are planted annually.",
]
استخراج المميزات من النصوص
نماذج تعلم الآلة تتعلم من المميزات الوصول لأهداف التعلم. هذه المميزات يطلق عليها (Features) هي خلاصة تنقيحنا للبيانات واستخراج ما نظن أنه مفيد لتعلم الآلة. هذا في حال كان التعلم عن طريق الاشراف حيث نزود النموذج ببيانات التدريب والعناصر المستهدفة، كما أن التعلم الغير اشرافي يستخدم أيضاً لترميز النصوص.استخراج المميزات يمر بأربع مراحل أساسية بالإمكان الاستزادة عليها حسب سياق المشكلة ونوع الهدف المراد للآلة أن تستهدفه. الخطوة الأولى تهدف لاستخلاص الكلمات من خلال فصلها عن الجمل. تلي هذه الخطوة إزالة المستبعدات وهي تلك الكلمات التي نستبعدها من سلسلة الكلمات المستخلصة ليسهل علينا معالجة اللغة. يمكننا تحديد هذه المستبعدات عن طريق الانتباه لكثرة تكرارها كحروف الجر (مثلاً: في، على، من، إلى) وحروف العطف والاستفهام والشرط. لا يوجد تعريف واضح لهذه المستبعدات ولا قائمة بالكلمات التي تشملها سواءً باللغة الإنجليزية أو العربية لعدم وجود توافق علمي شامل عما يمكننا استبعاده. على الرغم من ذلك فهناك مكتبات توفر قائمتها من هذه المستبعدات يمكن استخدامها بسهولة. ولتبسيط المفهوم، فيمكننا اعتبار الكلمات المستبعدة هي كل تلك الكلمات التي لا تحمل معنى بصفتها الفردية و التي تحتاج لوضعها في سياق أو مضافة لكلمات أخرى. أول من اقترح إزالة هذه الكلمات هو العالم (Hans Peter Luhn) في عام ١٩٥٩ م.
بعد استخلاص الكلمات من النصوص نحتاج لاستعادة جذورها حتى تصل كل كلمة إلى جذرها. بالنسبة للغات التي تُشكل في أشكال حروف كبيرة وأخرى صغيرة كاللغة الإنجليزية، فيتوجب علينا استخدام نمط واحد لشكل هذه الحروف، أي تحويل جميع الحروف لحروف صغيرة، مثلاً. أما بالنسبة للغة العربية فيتوجب علينا الانتباه لتصحيح الكلمات التي تكتب خطأً بالهاء أو التاء المربوطة مثل: "مكتبة" لتصحيح "مكتبه"، وهكذا. الخطوة الرابعة هي إزالة علامات الترقيم والأحرف الخاصة والكلمات التي يبلغ طولها حرفاً واحداً.
استخراج الكلمات
يمكن استخراج الكلمات باستخدام الأكواد المذيلة بالأسفل مع العلم أن مكتبة (Keras) تقدم واجهات (API) تقوم بهذه العملية.# Extracting the tokens using NLTK
# We need to serialize the text to splits the works into tokens
nltk_tokens = []
for text in corpus:
pre_text = pd.Series(text).str.cat(sep=' ')
nltk_tokens.append(word_tokenize(pre_text))
print(nltk_tokens)
وهنا باستخدام المكتبة:
# Extracting the tokens using Keras
ks_tokens = []
for text in corpus:
ks_tokens.append(keras_text_to_word_sequence(text))
print(ks_tokens)
لو أخذنا أول جملة في النص الذي اخترناه من موسوعة ويكيبيديا، فإن مخرجات هذ الخطوة عبارة عن متجه يحتوي على الكلمات المكونة للجملة الأولى كما في الشرح التالي:

تهيئة الكلمات المستخرجة
تهيئة الكلمات تشمل الخطوات التي ذكرناها سابقاً والتي تشمل إزالة المستبعدات و استعادة جذور الكلمات و إزالة علامات الترقيم و الأحرف الخاصة و الرموز المكونة من حرف واحد. بالامكان تحميل الكلمات المستبعدة في اللغة الانجليزية من المكتبة الأكثر شيوعاً في معالجة اللغة الطبيعية (nltk) على النحو التالي:from nltk.corpus import stopwords
# Retriving the stop words from the library
stop_words = set(stopwords.words('english'))
for i in range(0, len(ks_tokens)):
ks_tokens[i] = [w for w in pd.Series(ks_tokens[i]) if not w in stop_words]
من أمثلة الكلمات المستبعدة، الكلمات التالية: ['on', 'other', 'of', 'him', 'didn', 'have', 'haven', 'or', 'won', 'couldn']. نتاج هذه الخطوة على متجه الكلمات للجملة الأولى توضحه الصورة التالية:

يتطلب علينا الآن استعادة جذور الكلمات و سننفذ هذه الخطوة على النصوص الانجليزية باستخدام خوارزمية (Porter) على النحو التالي:
يتطلب علينا الآن استعادة جذور الكلمات و سننفذ هذه الخطوة على النصوص الانجليزية باستخدام خوارزمية (Porter) على النحو التالي:
# We will use Porter algorithm to reduce the words. Porter has 5 phases of word reductions:
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
لن نفصل في طريقة عمل هذه الخوارزمية، لكن لو أخذنا مثال كلمة (Eating) فإن الخورازمية تعمل على ازالة اللواحق لأصل الكلمة و تردها للجذر (Eat).
علينا الآن المرور على الكلمات المستخرجة و استعادة جذورها:
for tokens in ks_tokens:
for i in range(0, len(tokens)):
tokens[i] = porter.stem(tokens[i])
أصبح المتجه المستخلص من الجملة الأولى من النص بهذا الشكل:

الأكواد التالية ستعمل على إزالة الأرقام و علامات الترقيم و الأحرف الخاصة كما تقدم:
الأكواد التالية ستعمل على إزالة الأرقام و علامات الترقيم و الأحرف الخاصة كما تقدم:
for i in range(0, len(ks_tokens)):
new_ks_tokens = []
for tok in ks_tokens[i]:
tok = tok.translate(str.maketrans('', '', string.punctuation))
if tok != "" and len(tok) > 1 and (tok.isnumeric()==False):
new_ks_tokens.append(tok)
ks_tokens[i] = new_ks_tokens
وهكذا يصبح شكل المتجه النهائي بعد تهيئة هذه النصوص على هذا النحو:
ترميز النصوص
تحتوي الخطوات السابقة على العديد من الحلقات المتكررة ويمكن بسهولة أن تكون مكلفة للغاية خصوصاً إذا زاد عدد الكلمات بشكل كبير. وبالتالي ، سوف نكرر الخطوات السابقة باستخدام أسطر قليلة من التعليمات البرمجية باستخدام مكتبة (Keras):from keras.preprocessing.text import Tokenizer
# First step is to get an instance of the tokenizer class
tok = Tokenizer()
# Keras can fit our corpus in a single call
tok.fit_on_texts(corpus)
بالامكان الآن استطلاع تردد كل كلمة في المتجهات و عدد تكرارها في كل جملة على النحو التالي:
# Let's explore what is the content of the tokenized corpus
print('The frequency of each word in the corpus:')
print(tok.word_counts)
![]()
نستطلع فيما تبقى من هذه المقالة، طرق الترميز لمتجهات الكلمات بعد تنقيحها و معالجتها.
الترميز الساخن
يقصد بالترميز الساخن بناء متجهات تحمل جميع المفردات الموجودة في القاموس النصي المدخل ويكون حجم المتجه مساو لعدد الكلمات المستخرجة. يحتوي عناصر كل متجه على قيم تساوي الصفر أو الواحد. عدد المتجهات يساوي عدد الجمل النصية المدخلة. سمي بالساخن نظراً أنه يشغل العناصر التي تظهر في الجملة بقيمة ١ عند ظهور الكلمة كما في المثال التالي:print(tok.texts_to_matrix(corpus, mode='binary'))
![]()
الصورة التالية توضح ترميز الجملة الأولى على حسب ظهور الكلمات في القاموس.
 يرجى التنبه أن طريقة الترميز هذه افقدتنا ترتيب الكلمات، فنستطيع أن نتعلم من المتجه وجود الكلمة من عدمها لكن دون ترتيب الظهور.
يرجى التنبه أن طريقة الترميز هذه افقدتنا ترتيب الكلمات، فنستطيع أن نتعلم من المتجه وجود الكلمة من عدمها لكن دون ترتيب الظهور.
الترميز العددي
هذا النوع من الترميز مشابه لسابقه إلا أنه عوضاً عن استخدام القيمة ١، نستخدم تردد الكلمة في نفس الجملة.# Encoding the frequency of each word in the sentence
print(tok.texts_to_matrix(corpus, mode='count'))
![]()
يستخدم لوصف هذا النوع من الترميز مصطلح ([Frequency-based vectorization) وهناك طرق مشابهة للترميز العددي أو الترددي أشهرها (TF-IDF). ويمكن حساب الترميز بهذه الطريقة بناء على عدد الظهور لكلمة معينة على اجمالي عدد الكلمات في المستند.
# Encoding the frequency of each word in the sentence (TFIDF)
print(tok.texts_to_matrix(corpus, mode='tfidf'))
استخدام نموذج لتضمين الكلمات
في هذه النوع من الترميز، نعول على تعلم الآلة في بناء نموذج لحساب دلالة الكلمة بدلاً من ترميز ظهورها في الجملة. هذه الطريقة تعرف بمصطلح (Word Embedding). يتم بناء متجهات للكلمات بناءً على المسافة بين كل متجه وآخر. لبناء هذا النموذج، نستخدم شبكة عصبية لتتعلم ربط هذه المتجهات لبناء دلالة ضمنية تتنبأ بالكلمات المحيطة بها.تكرر للتو في الفقرة السابقة كلمة دلالة في أكثر من موضع، فما الدلالة التي نبحث عنها؟ الدلالة المقصودة هنا هي كيف لنا أن نعرف أن كلمتين مختلفتين في الحروف تتشابهان في المعنى؟ كلمة "تعلم"و كلمة "دراسة" كلاهما يحملان نفس الدلالة لكن كل كلمة منهما لا تشتركان في الحروف و لا في الأطوال. دلالة المعنى في اللغة الطبيعية تأتي في كيفية استخدام الكلمات في السياق وكيف تستخدم الكلمة مع نضيراتها في نفس الجملة. سنتطرق لكيفية بناء هذه النماذج التي تتنبأ بضمنية الكلمة ثم نستخدم بعض النماذج المدربة مسبقاً.
يوجد نموذجان واسعا الانتشار الأول Word2Vec و الآخر GloVe. لبناء نموذج محاكي لطريقة بناء متجهات Word2Vec نحتاج المكتبات التالية للتسهيل:
import gensim
from gensim.models import Word2Vec
# Building a word2vec model typically is very expensive, so we need to keep in mind the multiprocessing
# approach option
import multiprocessing cores = multiprocessing.cpu_count()
# Parameters
# size (int, optional) – Dimensionality of the word vectors.
# window (int, optional) – Maximum distance between the current and predicted word within a sentence.
# min_count (int, optional) – Ignores all words with total frequency lower than this.
# workers (int, optional) – Use these many worker threads to train the model (=faster training with multicore machines).
model = gensim.models.Word2Vec (ks_tokens, window=10, size=150, min_count=1,workers=10)
الرسم التفاعلي التالي يرسم بشكل مقتطع طريقة بناء هذا النموذج حيث تُبنى شبكة عصبية من طبقة مخفية واحدة. هذا النموذج يُمكننا بسهولة مقارنة المفردات عن طريق تعلم التفاعل الضمني المتوفر من خلال النص المدخل.
 بناء النموذج على عدد قليل من الكلمات ليس ذو قيمة، وذلك نظراً لعدم كفاية النصوص التي تمكن النموذج من تنبؤ المسافات بين كل متجه كما توضحه الصورة التالية. كما أن تكلفة بناء نماذج Word2Vec مرتفعة حيث تستغرق مساحة من الوقت و الذاكرة العشوائية عند البناء. وفي كثير من الأحيان، نلحظ أن بناء نموذج Word2Vec على قاعدة بيانات صغيرة سرعان ما ينتج عنه نموذجاً يكون مضاعفاً لحجم البيانات الأساسي. وعليه بالامكان استخدام نماذج تم تدريبها مسبقاً على بيانات أصغر بالحجم و حققت دقة عالية في بناء المتجهات الضمنية للكلمات.
بناء النموذج على عدد قليل من الكلمات ليس ذو قيمة، وذلك نظراً لعدم كفاية النصوص التي تمكن النموذج من تنبؤ المسافات بين كل متجه كما توضحه الصورة التالية. كما أن تكلفة بناء نماذج Word2Vec مرتفعة حيث تستغرق مساحة من الوقت و الذاكرة العشوائية عند البناء. وفي كثير من الأحيان، نلحظ أن بناء نموذج Word2Vec على قاعدة بيانات صغيرة سرعان ما ينتج عنه نموذجاً يكون مضاعفاً لحجم البيانات الأساسي. وعليه بالامكان استخدام نماذج تم تدريبها مسبقاً على بيانات أصغر بالحجم و حققت دقة عالية في بناء المتجهات الضمنية للكلمات.

سنستخدم نموذج GloVe وهي خوارزمية تم تدريبها على نصوص من موسوعة وكيبيديا و متوفرة من جامعة ستانفورد على هذا الرابط . الأكواد التالية ستعمل على تحميل النموذج واستخدامه.
سنستخدم نموذج GloVe وهي خوارزمية تم تدريبها على نصوص من موسوعة وكيبيديا و متوفرة من جامعة ستانفورد على هذا الرابط . الأكواد التالية ستعمل على تحميل النموذج واستخدامه.
import numpy as np
from scipy import spatial
embeddings_dict = {}
with open("models/glove.6B.50d.txt", "r") as file:
for line in file:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], "float32")
embeddings_dict[word] = vector
لو سألنا النموذج ماهي الكلمات القريبة من الكلمة ('book') فستكون الاجابة مقاربة للتالي:
['book',
'books',
'story',
'biography',
'novel',
'writing',
'wrote',
'author',
'titled',
'published'].
الصورة التالية توضح المتجهات المتقاربة لحد ١٠٠ كلمة لكل متجه.
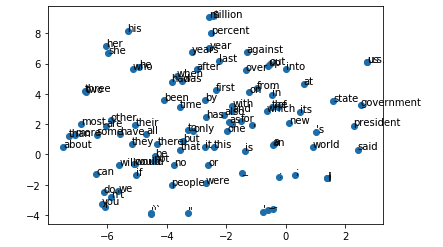
الرسم البياني في الصورة السابقة مبني على حساب فرق المسافة بين المتجهات. هناك عمليات رياضية مختلفة تُستخدم لحساب العلاقة بين المتجهات. الأكواد التالية تحسب العلاقة بين المتجهات باستخدام (Euclidean) أو (Cosine Similarity).
الرسم البياني في الصورة السابقة مبني على حساب فرق المسافة بين المتجهات. هناك عمليات رياضية مختلفة تُستخدم لحساب العلاقة بين المتجهات. الأكواد التالية تحسب العلاقة بين المتجهات باستخدام (Euclidean) أو (Cosine Similarity).
# Example 1
x = embeddings_dict['book']
y = embeddings_dict['notebook']
math.sqrt(sum([(a - b) ** 2 for a, b in zip(x, y)]))
---
5.506975291916892
# Example 2
x = embeddings_dict['book']
y = embeddings_dict['notebook']
spatial.distance.cosine(x,y)
---
0.6004519462585449
تحديات حول ترميز النصوص
الحفاظ على الترتيب
الترميز باستخدام المتجهات يستند على فهرس الكلمات الموجودة في القاموس وكما تطرقنا في المثال بداية المقال أن الترتيب في الترميز الساخن يفقدنا الحفاظ على ترتيب الكلمات في الجملة. هناك حلول مكلفة لحل هذه المشكلة عن طريق بناء متجهات تعبر عن الجملة الواحدة بدلاً من متجه واحد لكل جملة. اختيار الترميز المناسب في هذه الحالة يعود للنموذج الذي سيتعلم من هذه النصوص فبعض النماذج بامكانها تحقيق أداء مقبول دون الحاجة للاكتراث بالترتيب.طول المتجهات
ترميز المستندات باستخدام الفهرس مكلف إذا ما زاد عدد المفردات المميزة في المستند. زيادة هذ الأطوال ينتج عنه تمثيل معقد و متناثر لهذه المتجهات.التحيز و فقدان الكلمات
النصوص تحمل معان تعبيرية يسهل على الانسان ادراكها من النص كمعرفة لمن يعود إليه الضمير الغائب أو الضمير المتصل وغيرها من التحديات التي تفقد إدراكها نماذج تعلم الآلة. سرعان ما تنحاز هذه الضمائر لجنس معين في الخطاب إذا ماوجد هذا الانحياز طريقه إلى البيانات التي تم استخدامها لتدريب النموذج. لنأخذ مثالاً لتوضيح الفكرة:النموذج كان منحازاً لتضمين ("مسن" أو "قديم") لكلمة "رجل" وكانت الثانية من التشابه بينما كلمة "ثمين" كانت ضمنياً أقرب لكلمة "رخيص".
نماذج التضمين التي استخدمناها تكون عاجزة تماماً عند وجود كلمة جديدة لم يسبق للنموذج التعرف عليها. النموذج سيلوح بخطأ برمجي في حال كانت الكلمات المدخلة جديدة على قاموس النموذج.
سنكمل باذن الله مجالات استخدام النصوص في تعلم الآلة في مقالات قادمة. جميع الأكواد المستخدمة في هذه المقالة متوفرة على مستودع البيانات على هذا الرابط. كما يمكن الاطلاع على كيفية تصنيف النصوص حسب المشاعر في مثال تحدثنا عنه سابقاً على هذا الرابط.